트라이(Trie)의 형태
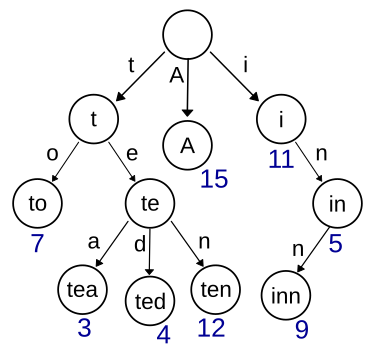
Trie: 트라이(Trie)란 문자열을 저장하고 효율적으로 탐색하기 위한 트리 형태의 자료구조- 위에 보이는 트리의 루트에서부터 자식들을 따라가면서 생성된 문자열들이 트라이 자료구조에 저장되어 있다고 볼 수 있다. 저장된 단어는 끝을 표시하는 변수를 추가해서 저장된 단어의 끝을 구분할 수 있다.
DFS 형태로 검색을 해보면 사진의 번호에 나와있듯이 to, tea, ted, ten, A, i, in, inn이라는 단어들이 자료구조에 들어가 있음을 알 수 있다.
트라이(Trie)의 예시
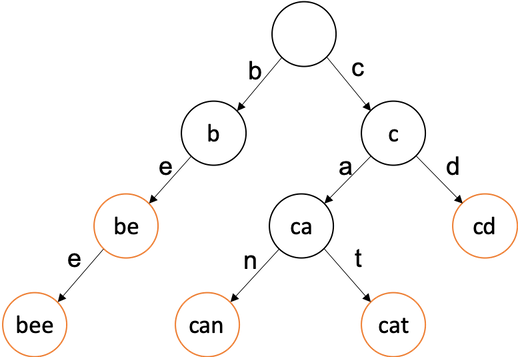
- 주황색으로 된 노드들이 입력된 문자열들이다.
- 현재
be, bee, can, cat, cd가 들어가 있다.
사용목적
목적
- 문자열의 탐색을 하고자할 때 시간복잡도를 보면 알 수 있다. 단순하게 하나씩 비교하면서 탐색을 하는것보다 훨씬 효율적이다. 단, 빠르게 탐색이 가능하다는 장점이 있지만 각 노드에서 자식들에 대한 포인터들을 배열로 모두 저장하고 있다는 점에서 저장 공간의 크기가 크다는 단점도 있다.
- 검색어 자동완성, 사전에서 찾기, 문자열 검사 같은 부분에서 사용할 수 있다.
시간 복잡도
- 제일 긴 문자열의 길이를
L 총 문자열들의 수를 M이라 할 때 시간복잡도는 아래와 같다.
- 생성시 시간복잡도:
O(M*L), 모든 문자열들을 넣어야하니 M개에 대해서 트라이 자료구조에 넣는건 가장 긴 문자열 길이만큼 걸리니 L만큼 걸려서 O(M*L)만큼 걸린다. 물론 삽입 자체만은 O(L)만큼 걸린다.
- 탐색시 시간복잡도:
O(L), 트리를 타고 들어가봤자 가장 긴 문자열의 길이만큼만 탐색하기 때문에 O(L)만큼 걸린다.
트라이(Trie)를 이용한 기본 문제
백준 온라인 저지 5052번
